Workshop on text input methods – 2011
ఇలాంటి వ్యాసాలు కూడా పుస్తకంలో రాయొచ్చు – అని చాటి చెబుతూ, మొదటి వ్యాసంతో శ్రీకారం చుడుతున్నా 🙂
ఈ వ్యాసం – ఇటీవలే (నవంబర్లో) జరిగిన ఒక వర్క్ షాపు లో ప్రచురించబడిన పరిశోధన పత్రాల సంకలనం గురించి. ప్రధానంగా ఇందులో ఆసియా దేశాల లిపులను కంప్యూటర్లో టైప్ చేయడం గురించి చేసిన పరిశోధనల గురించి రాసిన వ్యాసాలు ఉన్నాయి. ఉన్నవి పదే కానీ, నా మట్టుకు నాకు చాలా విషయాలు తెలిసినట్లు అనిపించింది. అక్షరల స్థాయిలో భాషా సంబంధిత సాంకేతికత గురించి నాకు ఆసక్తి. అందుకే నాకు ప్రస్తుతం సంబంధం లేకున్నా చదివాను. వ్యాసాల వారీగా ఒక చిన్న పరిచయం.
Workshop on Advances in Text Input Methods (WTIM-2011) :
“Challenges in Designing Input Method Editors for Indian Lan-guages: The Role of Word-Origin and Context” – మొదటిది నా ప్రమేయం ఉన్నది కనుక, ఎంతైనా చెప్పగలను. కానీ, ఆ కారణం చేత మొత్తం స్థలం తినేయకూడదు కదా 🙂 ఇక్కడ ప్రధానంగా రెండు కమర్షియల్ సిస్టమ్స్ తీసుకుని, వాటి పనితీరును, వాటి ద్వారా వచ్చిన ఫలితాలను “భాష” కోణం నుంచి పరిశీలించాక చేసిన విశ్లేషణలు ఈ వ్యాసంలో ఉంటాయి. ఎక్కువ మాట్లాడను.
Discriminative Method for Japanese Kana-Kanji Input Method – జపాన్ లిపిలో మూడు లిపులు ఉంటాయట. హిరాగన, కటకన (రెంటిని కలిపి కాన అంటున్నారు), కంజి. మొదటి రెండు – “syllabic” లిపులు. మూడవది చైనీస్ లిపి ఆధారంగా ఉండే అక్షరాలు అని తెలిపింది వికీ. మన గూగుల్ ట్రాన్స్లిటేరేట్ లో మనం ఇంగ్లీషు కీబోర్డుతో “phonetic” గా రోమన్ అక్షరాలు టైపు చేస్తే, తెలుగులోకి మారుస్తుంది ఆ మృదులాంత్రం (software). ఆ పధ్ధతి లో జపాన్ లిపి గురించి ఆలోచిస్తే, రోమన్ అక్షరాలు టైప్ చేస్తే, వాటిని కాన లోని మార్చి..ఆపై కంజి లోకి మార్చాలి అనమాట. ఇందులో ఉండే ఇబ్బందులు వాటి గురించి పరిశోధనలు ఉన్నాయి కానీ, వీళ్ళు అందరూ ఉపయోగించే “probabilistic” పధ్ధతి కాకుండా “discriminative” పధ్ధతి ఉపయోగించి ప్రయోగం చేసి, దాని ఫలితాలను ఇందులో రిపోర్ట్ చేసారు. ఎంత గొప్పగా ఉంది అన్న విశ్లేషణ పక్కన పెడితే, మామూలుగా వివిధ భాషలు కంప్యూటర్ లో టైప్ చేసే పధ్ధతి పై ఉన్న ఆసక్తి వల్ల నాకు చదవదగ్గది గానే అనిపించింది.
Efficient dictionary and language model compression for input method editors– ఇది గూగుల్ జపాన్ నుండి, నిజజీవితంలో వారు తయారుచేసిన-జనం ఉపయోగిస్తున్న మృదులాంత్రం గురించి కావడం నాకు ఇందులో అన్నింటికంటే ఆసక్తి కలిగించిన అంశం. అంతర్జాలం ద్వారానే కాక గూగుల్ కొన్ని భాషల్లో డౌన్లోడ్ చేస్కుని డెస్క్టాప్ పై ఉపయోగించుకునే టూల్ కూడా ఇస్తోంది. బహుశా తెలుగు కూడా ఉందనుకుంటా, నాకు తెలీదు. కనుక, ఇలా డౌన్లోడ్ చేసుకుని ఉపయోగించే సౌలభ్యం కలిగిస్తున్నప్పుడు టన్నుల కొద్దీ సమాచారం డౌన్లోడ్ చేసుకోమ్మనడం అనవసరం కదా :). ఈ విధమైన ట్రాన్స్లితెరేషన్ పద్ధతిలో ఒక నిఘంటువుతో పాటు, కొన్ని వెల పదాల జంటలతో తాయారు చేసిన త్రాన్స్లితెరేషన్ నమూనా (language model) కూడా ఉంటుంది. ఈ రెంటినీ పనితీరు చెడకుండా కంప్రెస్ చేసి డౌన్లోడ్ చేస్కునే సాఫ్ట్వేర్ లో ఇమడ్చడం కోసం వీళ్ళు ఎలాంటి అల్గారితంస్ వాడారో ఈ వ్యాసంలో వివరించారు. ఇందాక అన్నట్లు, రోజూ చూసే సాఫ్ట్వేర్ కనుక, ఆనందంగా అనిపించింది ఇలా ప్రచురించడం. అలా మనభాషల గురించి కూడా ఎపుడన్నా వివరంగా రాస్తారని ఆశిద్దాం 🙂
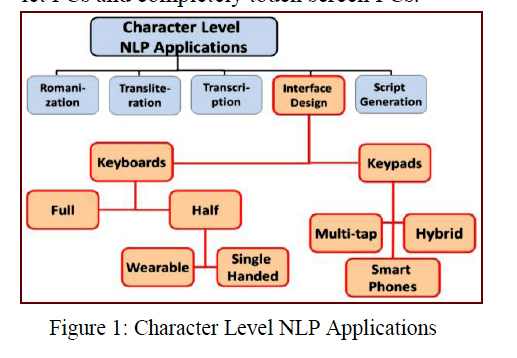
Different Input Systems for Different Devices – ఇది ఉర్దూ భాషకి వివిధ పరికరాలపై కీబోర్డులు రూపకల్పన చేయడం గురించి. మొబైల్ ఫోన్లపై, టాబ్లెట్ లపై, కంప్యూటర్లపై…ఇలా పరికరం బట్టి, పరికరంపై ఉన్న స్థలాన్ని బట్టి, కీబోర్డు రూపకల్పన అన్నింటిలోనూ ఒకటిగా ఉండడం కష్టం. అందువల్ల దీని తాలూక ఇబ్బందులు, పరిష్కారాలు కొంతమేరకు చర్చించారు. ఇందులో “Character level applications of NLP” అన్న భాగం నాకు అన్నింటికంటే నచ్చింది. ఆ విషయమై ఎప్పుడు నాకు సరైన చర్చ కనబడలేదు. ఇక్కడ కూడా పూర్తిగా లేదు కానీ, ఇందులో ఇచ్చిన బొమ్మ మాత్రం నాకు తెగ నచ్చేసింది. అలాగే, ఇందులో చూపిన డైనమిక్ కీబోర్డు ఆలోచన కూడా నాకు చాలా నచ్చింది.
An Accessible Coded Input Method for Japanese Extensive Writing – మళ్ళీ జపానుకి వచ్చేసాం. ఇందులో కాస్త వివరంగా ఉంది జపాన్ భాష లిపి రాసే పధ్ధతి గురించి, దాన్ని కంప్యూటర్ లో వాడడం గురించీ. పైన కాన నుంచి కంజి కి మార్చే పధ్ధతి గురించి రాసారు. వీళ్లేమో – మన ఆర్.టీ.ఎస్. తరహాలో కాన, కొన్ని కంజి అక్షరాలకు ఆంగ్ల మ్యాపింగ్ లు సృష్టించి దాన్ని పైన పత్రంలో చెప్పిన తరహా మార్పిడి పద్ధతికి కలిపేసి కొత్త పధ్ధతి కనిపెట్టారు 🙂 అంటే, వీళ్ళ అభిప్రాయం లో ఇది “best of both worlds” అనమాట :). దీన్ని ఓ-కోడ్ అన్నారు. అంతకుముందు టీ-కోడ్ అని ఒక మ్యాపింగ్ ఉండేదట. దానితో పోలిస్తే, ఇది ఇరు ప్రపంచాల మంచినీ తనలో ఇముడ్చుకుంది అని అంటున్నారు. తరువాత చాలా భాగం జపనీస్ స్క్రిప్టు వల్ల అర్థం కాలేదు కానీ, కీబోర్డు ఎలా ఉండాలి? అని రాసిన భాగం నాకు నచ్చింది.
Error Correcting Romaji-kana Conversion for Japanese Language Education :ఇది కూడా మళ్ళీ జపనీస్ లిపి గురించే. కాకపోతే, ఈసారి వినియోగం వేరు. జపనీస్ నేర్చుకునే వారికోసం రూపొందించారట. సాధారణంగా జపనీస్ భాష నేర్చుకునే యురోపియన్లు ఇతరులు ఆ లిపి నేర్చుకోడం కష్టం కనుక, రోమన్ లిపిలో రాయడం నేర్చుకుంటారు (దాన్ని రోమాజి అంటారు). ఈ పత్రంలో వాళ్ళు టైప్ చేసే రోమాజి లో ఒకవేళ తప్పులు ఉంటే, వాటిని సరిదిద్ది సరైన కాన కి మార్చే పధ్ధతి కనిపెట్టారు. అలాగే, ఈ రాయడంలో జపనీస్ పదాలు కాక వేరే ఏవి వచ్చినా గుర్తించి, వాటిని అలా సరిదిద్దకుండా జాగ్రత్త పడతారు అంట. సాధారణంగా మార్కెట్లో ఉన్న ఇతర సాఫ్ట్వేర్లు జపనీస్ మాతృభాషగా గలవారికైతే, దీని ప్రత్యేకత ఏమిటంటే ఇది జపాన్ భాష నేర్చుకునే వారికి, నేర్పించేవరికీ ఉపయోగపడడం! ఇలా రెండు కోణాలూ ఆలోచిస్తూ పరిశోధనలు చేయడం నాకు నచ్చింది కానీ, ఈ విషయమై – ఇద్దరి మధ్యా గల తేడాల గురించి కాస్త వివరంగా చెప్పి ఉంటే బాగుండేదేమో!
From pecher to pêcher… or pécher: Simplifying French Input by Accent Prediction – ఇలా సాగుతూ ఉండగా మధ్యలో ఫ్రెంచి వచ్చేసింది! ఇది మైక్రోసాఫ్ట్ రెడ్మండ్ నుంచి. ఫ్రెంచి భాషలో ఉండే తరహా accented అక్షరాలను ఫ్రెంచి కీబోర్డు లేకుండానే, మామూలు ఆంగ్ల కీబోర్డుతోనే టైప్ చేయడం గురించి. టైటిల్ చూడగానే నాకు కాస్త ఆశ్చర్యం కలిగింది. ఎందుకంటే, మనం ఇన్పుట్ మెథడ్ అనగానే, రోమన్ లిపి కాని వాటి గురించి ఆలోచిస్తాం. ఇలా ఫ్రెంచికి కూడా అవసరం పడుతుందని, దాని గురించి పని చేస్తారని నేను ఊహించలేదు. అయితే, మామూలు ఫ్రెంచి మాతృభాష గలవారికి పెద్ద ఉపయోగ పడకపోవచ్చు కానీ, ఇతరులకి ఫ్రెంచి టైప్ చేయాలంటే పనికొస్తుంది అనుకుంటాను (వీళ్ళు దీన్ని ఎక్కడో డౌన్లోడ్ చేస్కోనిస్తే!!)
Phrase Extraction for Japanese Predictive Input Method as Post-Processing – ఇందులో కూడా మళ్ళీ జపనీస్ భాష కోసమే. పేరులో చెప్పినట్లు వాక్య భాగాలను (Phrases) టైప్ చేస్తున్న వాళ్లకి సూచనలు గా అందివ్వడానికి వీళ్ళు కనిపెట్టిన పధ్ధతి గురించి రాసారు. సాధారణంగా ఇలాంటి అసంపూర్ణ వాక్యాలను వెలికి తీయడం వాళ్ళు పని చేస్తున్న పెద్ద కార్పస్ లో ఉన్న అక్షరాల కాంబినేషన్ల గురించి లెక్కలు వేసే ముందు చేస్తున్నారంట. దీనివల్ల ఈ అసంపూర్ణ వాక్యాలను వెలికితీసే పధ్ధతి మార్చిన ప్రతిసారీ ఈ లెక్కలు మళ్ళీ చెయ్యాలి. టన్నుల కొద్దీ సమాచారం ఉన్నప్పుడు ఇది కష్టం కనుక, వీళ్ళ పద్ధతిలో ఆ లెక్కింపు ముగిశాకే ఈ వెలికితీత కార్యక్రమం చేస్తారట. ఇది యాహూ జపాన్ వారి పత్రం. మొత్తానికి ఆసక్తి కరంగానే ఉంది కానీ, నాకాట్టే అర్థం కాలేదు వాళ్ళ వర్ణన.
Robustness Analysis of Adaptive Chinese Input Methods – వచ్చేసింది చైనా! 🙂 చైనీస్ భాషలో టైప్ చేసే పద్ధతులపై నాకు తెలిసినంతవరకూ తక్కిన ఆసియా భాషలతో పోలిస్తే విరివిగా పరిశోధన జరిగింది. ఇప్పుడు ఈ పత్రంలో వివిధ పద్ధతులని పోల్చడానికి ఒక కొత్త ఫార్ములా కనిపెట్టారు. వీళ్ళ పరిశోధనలు, ఫలితాల కంటే కూడా నాకు కీబోర్డుల పనితీరు ని ఎలా పోల్చాలో, ఎలాంటి పద్ధతులు ఉంటాయో వివరించిన భాగం ఉపయోగకరంగా అనిపించింది.
ఈ సంకలనం సాన్కేతికంగానే ఉంటుందనీ, నేపథ్యం లేనివారికి అంత సులభంగా అర్థం కాకపోవచ్చనీ ఒప్పుకుంటాను. కానీ, ఆసక్తి ఉన్నవారు ఇంట్రడక్షన్ భాగాలు చదువవచ్చు. భాషకి సంబంధించినది కనుక, ఆసక్తికరంగా అనిపించవచ్చు కొందరికి. ఆసక్తి కలిగిన వారు ఈ ప్రొసీడింగ్స్ ఈ-వర్షన్ ని ఈ పీడీఎఫ్ ఫైలు లో చదవొచ్చు.



సి.ఏ.సి.యం – జనవరి ౨౦౧౨ సంచిక | పుస్తకం
[…] మొదలుపెట్టాను. మొన్నా మధ్య ఒక వర్క్షాప్ ప్రొసీడింగ్స్ పుస్తకం గురించి రాసినప్పుడు అలా సి.ఏ.సి.యం […]
kvrn
very nice. learned new things